Tokens Iterator

Contents
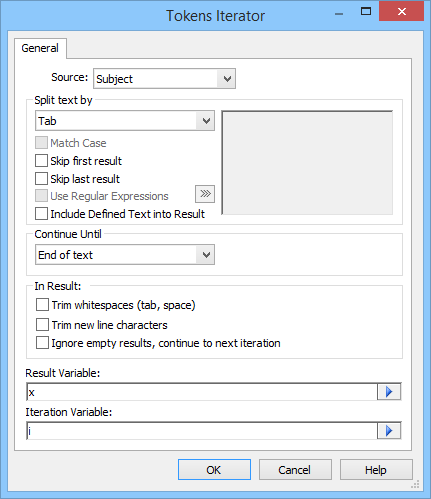
Used to extract data from text containing certain delimiters. Such as text in CSV format for example.
Source
Set text source, which is used to parse data from every iteration.
Split text by
Set delimiters to separate text
Match Case
Enables case-sensitive search of the string beginning.
Skip first result
Ignore first extracted token
Skip last result
Ignore last extracted token
Use Regular Expressions
Enables regular expressions usage for search of the string beginning.
Include Defined Text into Result
Enables addition of defined text to the beginning of the string parsed.
Continue Until
Set condition for end of iteration. The following operation modes are possible:
End of Text - The iteration ends when a end of text is reached.
Result variable is empty - The iteration ends when token placed to Result variable is empty.
Iteration variable greater than - The iteration ends when the number of cycles exceeds the specified value.
In Result
Trim whitespaces
Remove white space characters (space, tab) from the beginning and end of extracted token.
Trim new line characters
Remove new line characters (Carrage Return and Line Feed) from the beginning and end of extracted token.
Ignore empty results. continue next iteration
Perceive empty token as a significant.
Result Variable
Set name of the variable data to be parsed in.
Iteration Variable
Set variable name iteration number to be placed in.
See also