Regular Expression Iterator

Contents
Used to execute a set of components for regular expressions in specified text source. At the every iteration component will find the next regular expression in the text source. It will be parsed with iterator and stored in set of variables. After all a set of iterator components will be executed. Iterator will finish its job, if the line met its condition was not found.
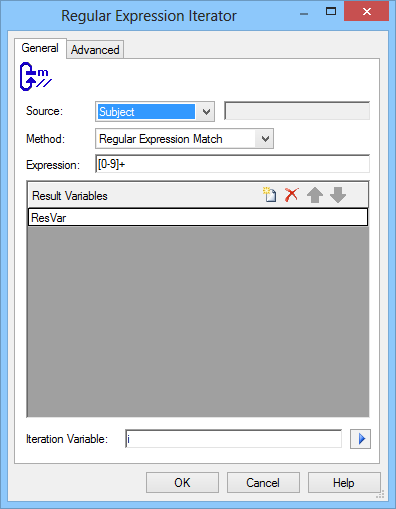
Source
Set text source, which is used to parse data from every iteration.
Expression
Set regular expression.
Result Variables
A list of variables which is used to parse data.
Iteration Variable
Set variable name iteration number to be placed in.
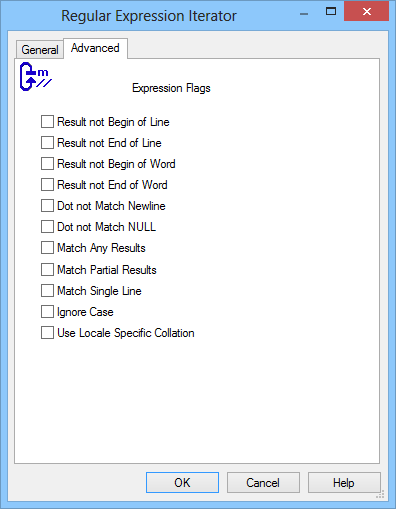
Result not Begin of Line
When this flag is set then result does not represent the start of a new line.
Result not End of Line
When this flag is set then result does not represent the end of a line.
Result not Begin of Word
When this flag is set then result can never match the start of a word.
Result not End of Word
When this flag is set then result can never match the end of a word.
Dot not Match Newline
Specifies that the expression "." does not match a newline character. This is the inverse of Perl's /s modifier.
Dot not Match Null
Specifies that the expression "." does not match a character null '\0'.
Match Any Results
Specifies that if more than one match is possible then any match is an acceptable result: this will still find the leftmost match, but may not find the "best" match at that position. Use this flag if you care about the speed of matching, but don't care what was matched (only whether there is one or not).
Match Partial Results
Specifies that if no match can be found, then it is acceptable to return a match [from, last) such that from!= last, if there could exist some longer sequence of characters [from,to) of which [from,last) is a prefix, and which would result in a full match. This flag is used when matching incomplete or very long texts.
Match Single Line
Equivalent to the inverse of Perl's /m modifier; prevents ^ from matching after an embedded newline character (so that it only matches at the start of the text being matched), and $ from matching before an embedded newline (so that it only matches at the end of the text being matched).
Ignore Case
Disable case-sensitive search
Use Locale Specific Collation
See also